
log4netの設定ファイルはSystem.Text.Encodingの初期値の違いを利用してUTF-8にBOMをつけるかつけないかの動作を変えています。
というわけで他のUnicode系の文字コードの場合初期設定はどうなっているのか調べていきます。
目次
- まずそもそもBOMとは一体何か
- 今回実験用に作成したコード
- Encoding.GetEncoding(“Shift_JIS”)
- Encoding.UTF8Encoding.GetEncoding(“UTF-8”)
- Encoding.UTF7Encoding.GetEncoding(“UTF-7”)
- Encoding.UnicodeEncoding.GetEncoding(“UTF-16”)
- Encoding.BigEndianUnicodeEncoding.GetEncoding(“UTF-16BE”)
- Encoding.UTF32 Encoding.GetEncoding(“UTF-32”)
- Encoding.GetEncoding(“UTF-32BE”)
- new UTF8Encoding()
- new UTF7Encoding()
- new UnicodeEncoding()
- new UTF32Encoding()
- まとめ
まずそもそもBOMとは一体何か
エンコード判定用にファイルの先頭に付ける数バイトの文字のこと。
テキストファイル上では省略されて見えないが、プログラミングで何も考えずにファイル流したらBOMの数バイトも読み込んでしまって思ったように動かない…なんてことも。その逆のパターンももちろんあります。
今回実験用に作成したコード
using System.IO;
using System.Text;
namespace ConsoleApp15
{
class Program
{
static void Main()
{
Encoding enc = Encoding.GetEncoding("Shift_JIS");
using (StreamWriter writer = new StreamWriter(@"C:\jikken\text.txt", false, enc)) {
writer.WriteLine("書き込みー");
}
}
}
}まあ出力するだけならこれくらいでいいですよね。
上記のコードでは”Shift_JIS”を設定していますが、この値を変えたり派生クラスを設定した場合にどの文字コードで出力されるのかを実験していきます。
Encoding.GetEncoding(“Shift_JIS”)
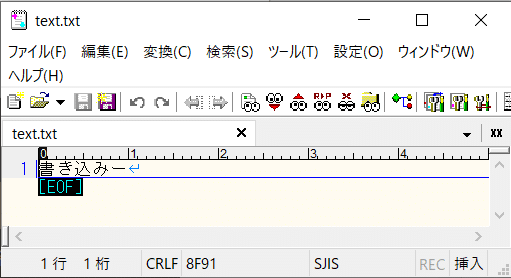
“Shift_JIS” はもちろんBOMはついていません。まあこれについては確認するまでもないかと思います。
だってShift_JISにBOMなんて存在しないんだもの。

コードページも932でごくごく普通のShift_JISになります。
Encoding.UTF8
Encoding.GetEncoding(“UTF-8”)
次は”UTF8″です。
UTF-8等ユニコード系の文字コードは世界的にみて使用頻度が高いからなのか、専用のクラスも用意されています。
こちらもencoding.getencoding(“UTF-8”)を実行した時と全く同じ挙動をします。
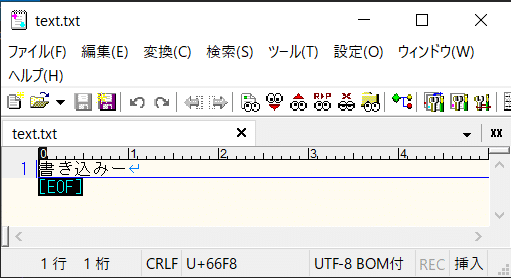
この方法でEncodingオブジェクトを作成するとBOMを指定してないにも関わらず、BOMが付きます。
こちら、コードレビューをしていてもうっかり見逃しがちなポイントになります。後々結果をよく見てみたらBOMが付いていた…なんてことも。テストをやり直すのは大変なので気を付けましょう。
Encoding.UTF7
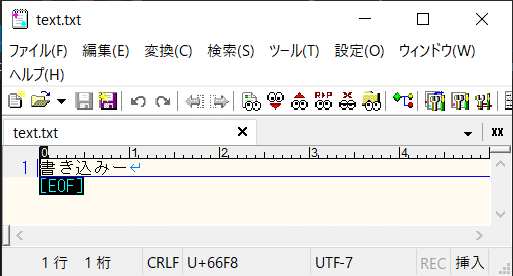
Encoding.GetEncoding(“UTF-7”)
UTF7を指定した場合はBOMが付きません。
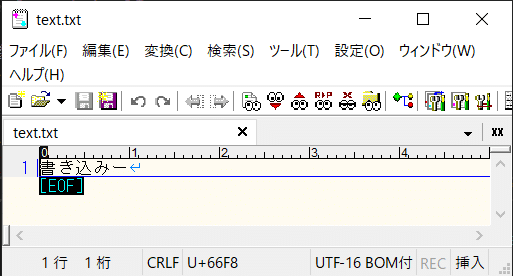
Encoding.Unicode
Encoding.GetEncoding(“UTF-16”)
Encoding.BigEndianUnicode
Encoding.GetEncoding(“UTF-16BE”)
Encoding.GetEncoding(“UTF-16BE”)の方はマイクロソフトの公式リファレンスには載っていないにも関わらず、試しに指定してみたら動きました。

Encoding.UTF32
Encoding.GetEncoding(“UTF-32”)
サクラエディタはUTF32に対応していないので都合上UTF16として読み込んでいます。
1文字1文字の間に制御文字が入っているのが分かります。(UTF16と比較するとUTF32は文字長が2倍になります。)
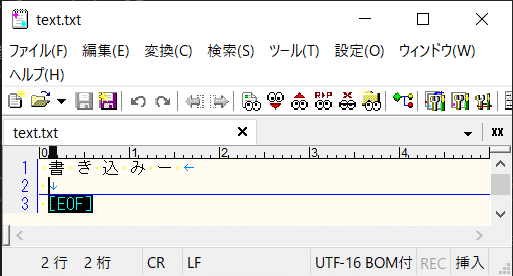
Encoding.GetEncoding(“UTF-32BE”)
UTF32BEで実行した結果もUTF16BEとしてサクラエディタの都合上読み込まれています。
1文字1文字の間に制御文字が入っているのが分かります。
そしてこちらには文字コードにはBOMと書かれていませんが、冒頭にBOMが入っています。
(Encoding.GetEncoding(“UTF-32”)の実行結果と比較するとBOMの分開始位置がずれていることが分かると思います。)
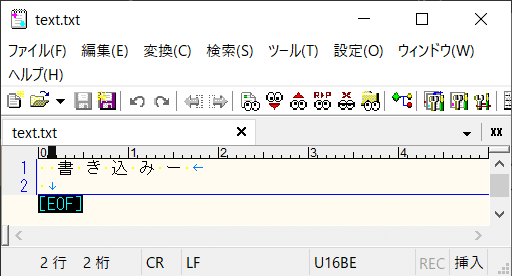
new UTF8Encoding()
ここからは派生クラスの実行になります。
結果を比較するとBOMが付いていないことが分かります。

new UTF7Encoding()
UTF7は指定方法を変えても動作結果に差は出ません。

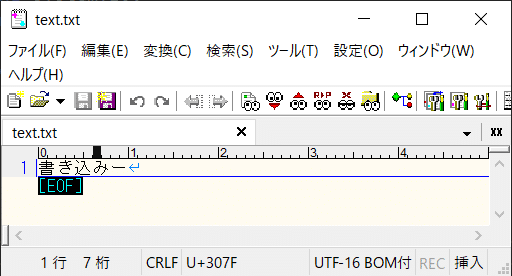
new UnicodeEncoding()
UTF16は指定方法を変えても動作結果に差は出ません。
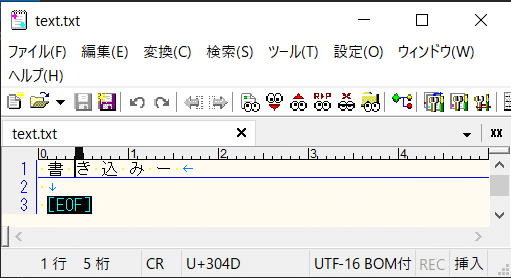
new UTF32Encoding()
UTF32は指定方法を変えても動作結果に差は出ません。
まとめ
今回の実行結果から以下のことがわかりました。
- UTF8だけプログラムの書き方によってBOMが付いたり付かなかったりする
- Unicode体系のその他の文字コードはEncodingオブジェクトの作り方では特に挙動に差が出ることはない
もちろん、引数で指定すればBOMを付けるのかBEにするのかは設定できます。
確実に挙動を指定したいのなら引数でカッチリ決めることをオススメします。